10分钟快速速通Claude Code泄露源码核心架构,里面居然藏了一个脏话彩蛋!
大家好,我是轩辕。
Claude Code泄露事件发生一天过去了,官方在泄露十多个小时之后,终于撤回了2.1.88版本。
相关的负责人也在X上承认了事件属实,这事算是石锤了。
有意思的是,我打开我手里的Claude Code问它认不认识这份代码,它直接表示相当熟悉,我也是差点没绷住。
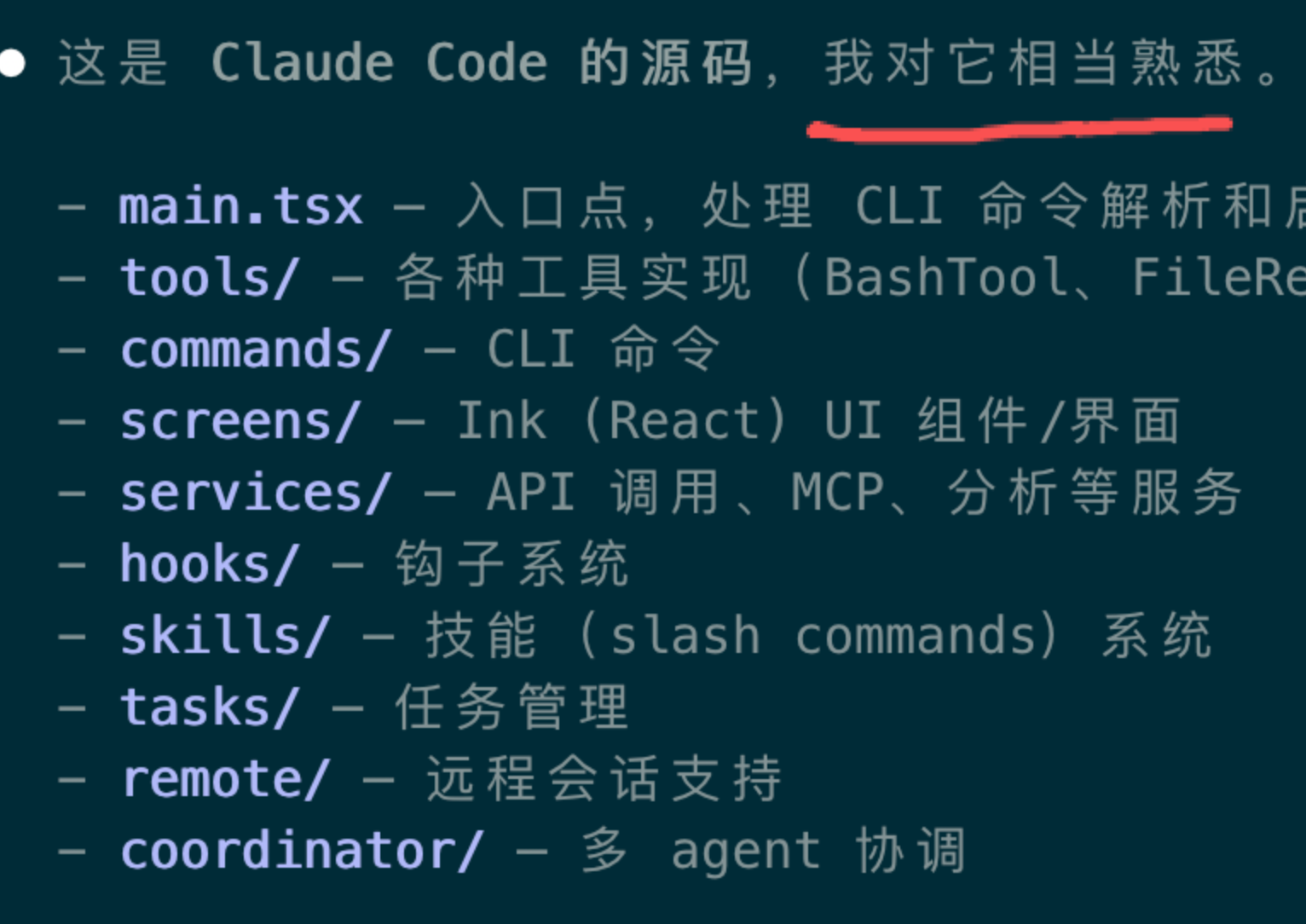
我带着Claude Code和Codex连夜加班,分析了这次泄露的源代码,做了一套完全免费的学习教程,供大家深入研究学习。

学习地址:
https://www.xuanyuancode.com/learn-claude-code
烧了我不少的token,如果觉得还不错,别忘了点赞支持下哦。
今天这篇文章,我用10 分钟,带你把它最重要最精华的部分搞清楚,包括核心工作引擎循环、提示词工程、工具的调用、上下文管理、MCP 协议、Skills,六个模块,全部拿下。
干货很多,建议收藏再看。
先建立一个整体印象
在进入细节之前,先来看一下整体的工作流程图。
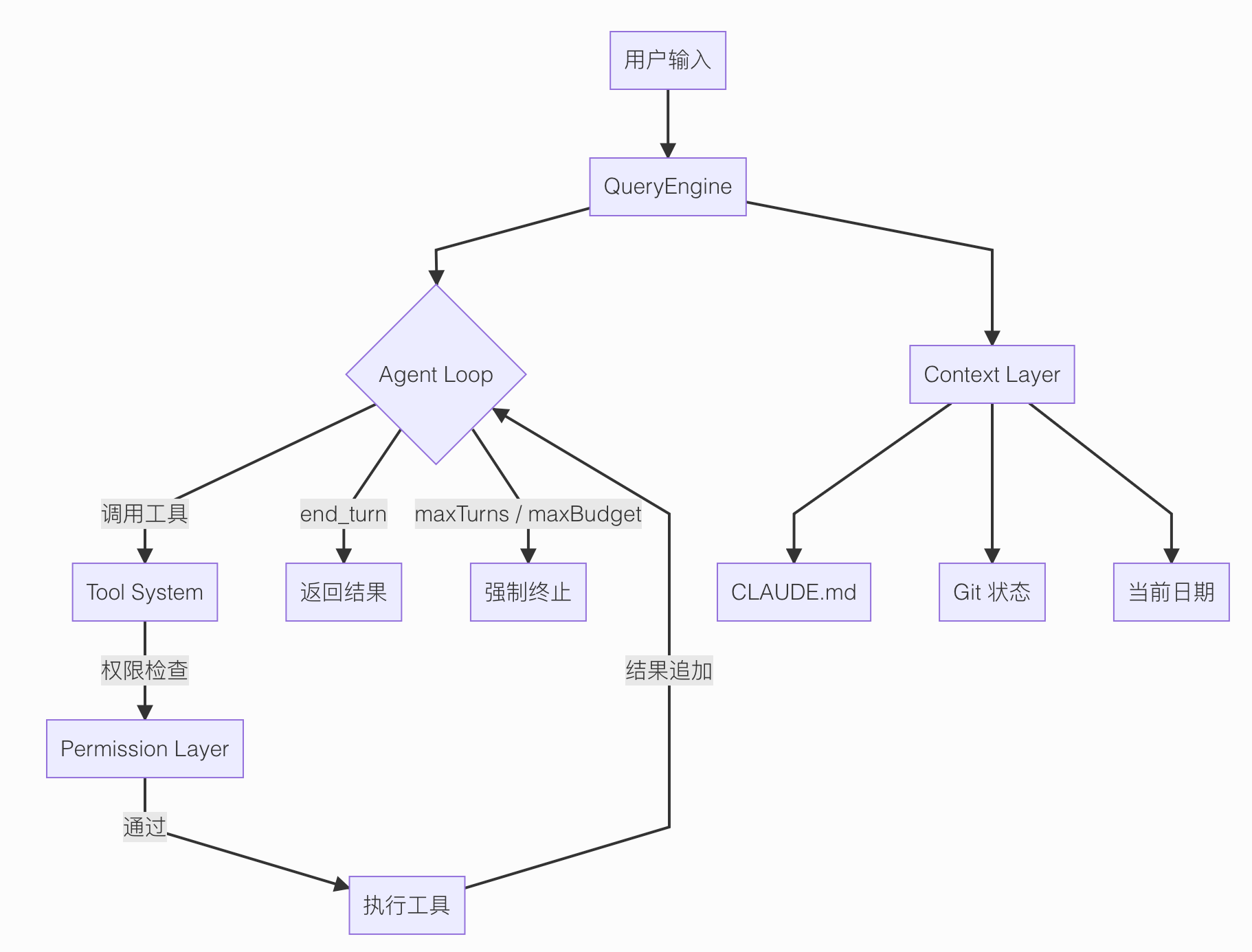
Claude Code 内容虽然很多,但总的来说,核心就一件事:通过一个循环不断调用工具,以及为了让这个循环能平稳运行的一套外围工程设计。这套外围工程设计也就是最近经常看到的Harness工程,网友戏称牛码工程。
你给它一个任务,它进入一个循环。
循环里不停地调工具——读文件、改代码、跑终端命令——每次工具跑完,把结果塞回对话历史,Claude 再看结果决定下一步干什么。
就这么一直转,转到任务完成,或者触发终止条件为止。
接下来具体看看这个核心循环引擎的实现。
第一块:核心工作引擎循环
核心逻辑藏在两个文件里:QueryEngine.ts 和 query.ts。
Claude API 的响应是流式的——一点点输出,代码用一个循环逐条处理每一段内容,大概是这样的:
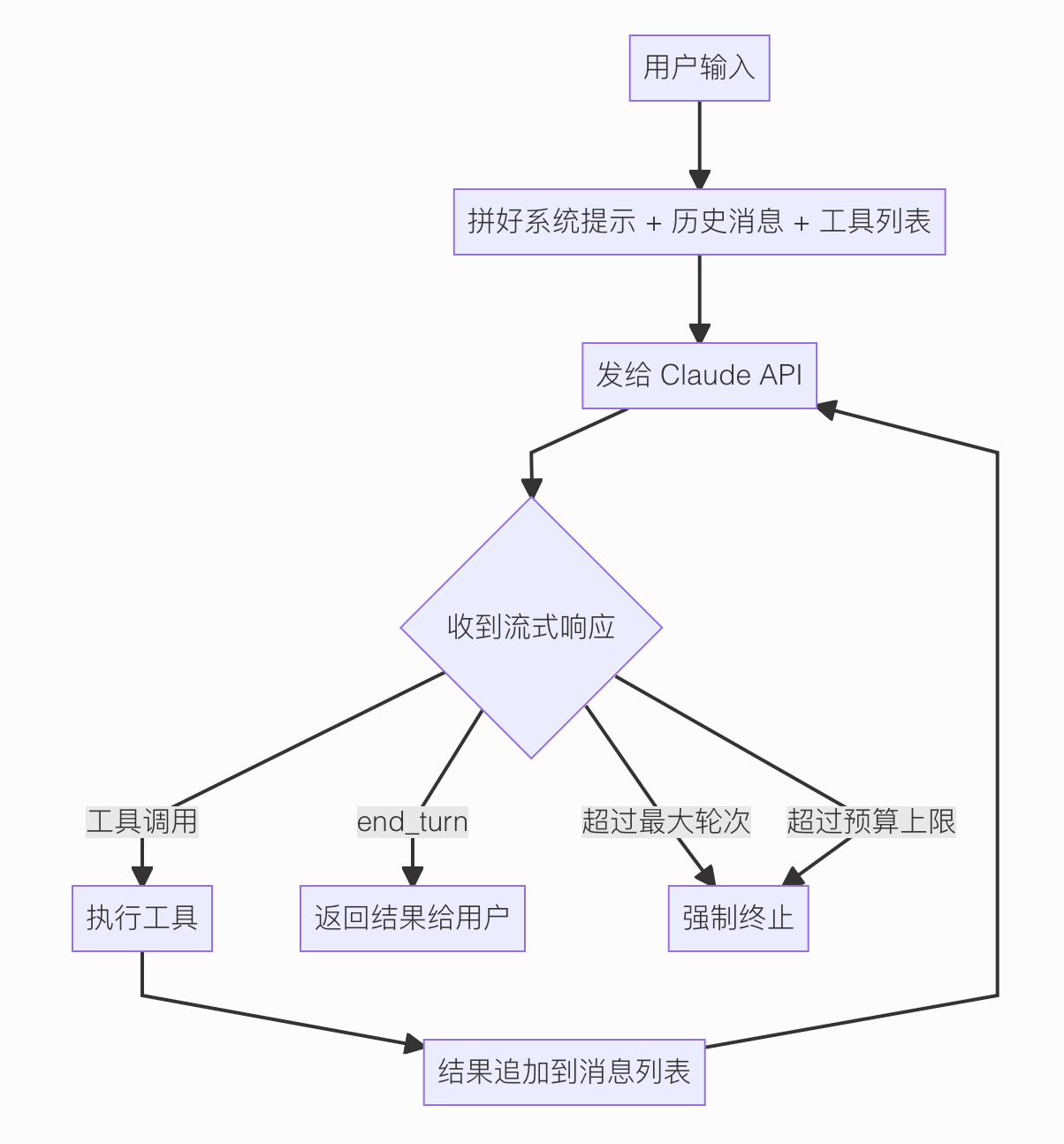
每调用一次工具,就是一轮。每轮结束,对话历史就多了一条工具结果消息。
下一轮把这些历史全部带上,模型看到工具结果再决定下一步——要么继续调工具,要么结束任务。
来看源码里核心循环的骨架,我把细节省掉,只留最关键的结构:

这就是 Agent 循环的本质,所有框架底层都是这个结构,换汤不换药。
但光是这个循环还不够看,Claude Code 在里面埋了两个重要的操作。
第一个,双重终止熔断。
Claude Code 同时设置了 maxTurns(最大轮次上限)和 maxBudgetUsd(最大预算上限)两个终止条件。
// QueryEngine.ts 第 146 行
maxTurns?: number
maxBudgetUsd?: number
然后在循环末尾,每轮结束都会检查预算:
// QueryEngine.ts 第 972 行
if (maxBudgetUsd !== undefined && getTotalCost() >= maxBudgetUsd) {
yield {
type: 'result',
subtype: 'error_max_budget_usd',
errors: [`Reached maximum budget ($${maxBudgetUsd})`],
}
return
}
为什么要两个?
只用轮次限制,有可能轮次没超但模型每轮都在生成大量 token,成本照样失控。
只用预算限制,有时候任务进入一个奇怪的死循环,一直花小额费用但永远不收敛,预算熔断太晚才触发。
两个一起才能互补——既防死循环,又防超支。
我们自己做 Agent 的时候,也可以参考这种设计。
第二个,Token 实时累计,不是事后结算。
它不是等一次完整对话结束才算用了多少 token,而是每收到一段流式响应,就立刻把这段的 token 用量累加进去。
来看源码:
// QueryEngine.ts 第 789 行
if (message.event.type === 'message_start') {
// 新消息开始,重置本条消息的计数
currentMessageUsage = EMPTY_USAGE
currentMessageUsage = updateUsage(
currentMessageUsage,
message.event.message.usage,
)
}
if (message.event.type === 'message_delta') {
// 流式增量,立刻累加
currentMessageUsage = updateUsage(
currentMessageUsage,
message.event.usage,
)
}
if (message.event.type === 'message_stop') {
// 一条消息结束,追加到全局总量
this.totalUsage = accumulateUsage(
this.totalUsage,
currentMessageUsage,
)
}
这样做的好处是:可以随时精确触发预算熔断,不会超了才知道。
Anthropic这是一点亏也不想吃的。
第二块:提示词工程
OK,循环搞清楚了,接下来看看 Claude Code 的提示词工程,看看它的提示词到底是怎么组织的。
很多人以为 Claude Code 背后就是一段超长系统提示词。
实际上不是。
它更像一套分层装配系统。不同信息放在不同层里,按当前状态动态拼出来。
大体上分为五个层级。
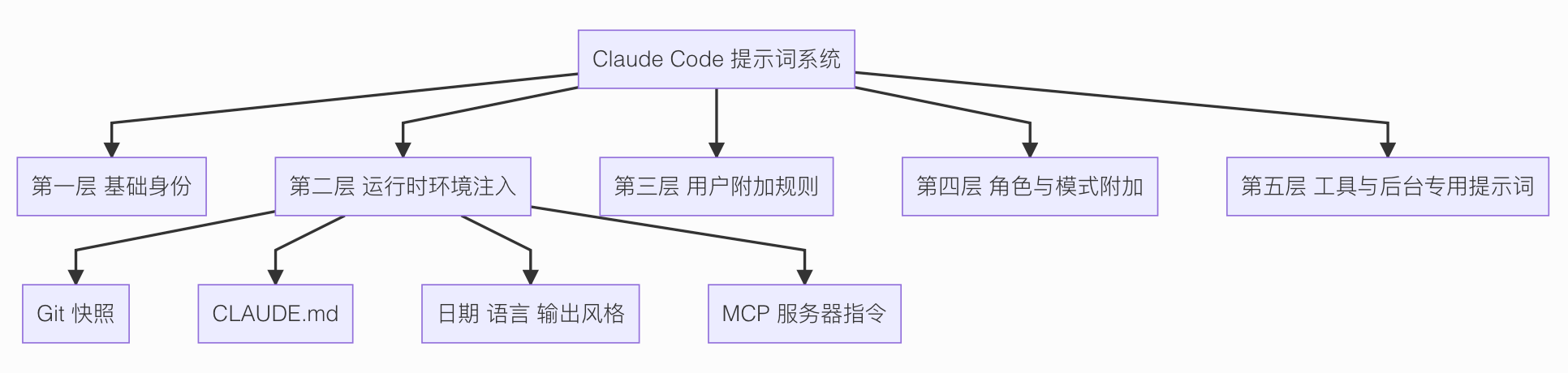
1:基础身份。
最底层先把 Claude Code 的身份钉死:它不是普通聊天机器人,而是面向软件工程任务的交互式 Agent。
这层决定的是总基调。
2:运行时环境注入。
这一层最重要。
Claude Code 每轮对话前,都会把当前环境里最关键的信息拼进去。
比如:
- Git 状态快照
CLAUDE.md- 当前日期
- 语言偏好和输出风格
- MCP 服务器附带的指令
这里你可以把它理解成:
先把“你现在在哪个项目、当前是什么状态、有哪些额外环境约束”告诉模型。
3:用户附加规则。
这层专门说用户自己主动加进去的系统级规则。
这一层更像是用户在告诉 Claude Code:
- 回复统一用中文
- 先给方案再改代码
- 不要碰某些目录
也就是长期生效的附加规则。
4:角色与模式附加。
这一层就是根据 Claude Code 当前扮演的角色,自动再补一段约束。
最典型的就是 Teammate。
当 Claude Code 作为子 Agent 被调用时,系统会自动告诉它:
- 你现在是谁
- 你不是主 Agent
- 你该怎么和上层通信
- 哪些输出别人其实看不见,必须走
SendMessage
所以这一层讲的不是“某个专项功能”,而是当前身份和协作模式带来的附加约束。
5:工具与后台专用提示词。
最后一层再分成两小类看。
第一类是工具级 prompt。
每个工具不只是一个函数定义,它还带自己的使用说明。
比如 Bash 工具的 prompt 会明确告诉模型:
- 什么时候该用 Bash
- 什么时候别乱用 Bash
- 读文件优先走专门的文件工具
这类 prompt 的作用,是帮模型在多个工具之间选对路。
第二类是后台专用 prompt。
这些 prompt 不是直接给用户看的,而是给一些专项流程用的。
比如:
/init- 记忆筛选
- 工具结果总结
- 上下文压缩
它们也有各自独立的提示词,但它们不是身份层,也不是用户自定义层,而是服务于某个后台子流程。
简单小结一下这五层提示词:
- 基础身份:你到底是什么
- 运行时环境:你当前所处的项目和环境
- 用户附加规则:用户额外加给你的长期规则
- 角色与模式附加:你这次扮演什么身份
- 工具与后台专用提示词:具体怎么执行和怎么支撑后台流程
要说明一下的是,上面这五层主要是系统提示词部分,不包含用户自己输入的消息。
第三块:工具系统
接下来是工具系统。
Claude Code 之所以比大模型更强大,核心原因就是,它背后接了一整套工具。
没有工具,它只是一个聊天对话模型。 有了工具,它才能真正去读文件、改代码、跑命令、联网、问用户、分任务。
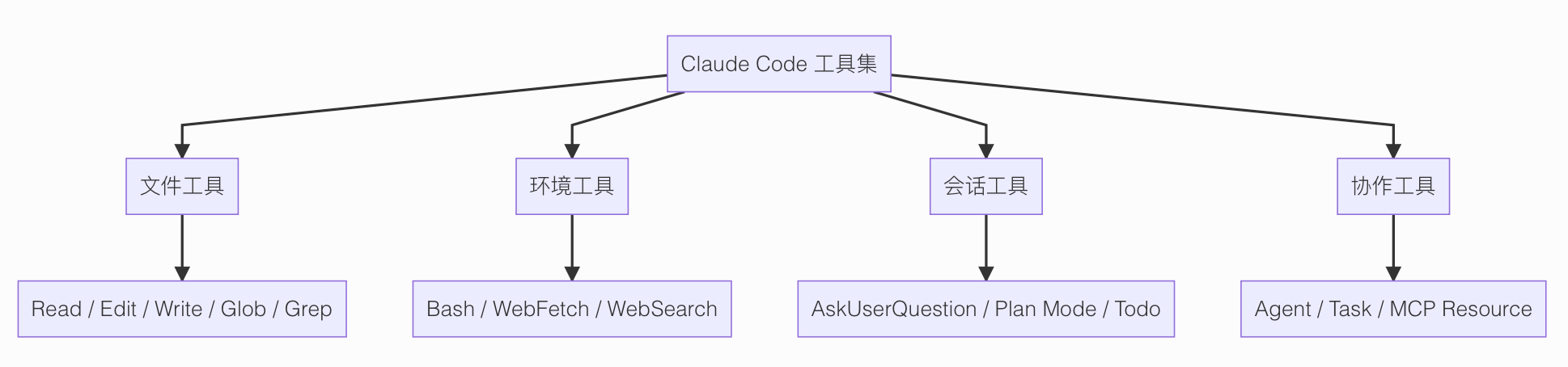
Claude Code内置的工具大体分为4大类。
第一类,文件工具。
这是 Claude Code 最常用的一组。
FileReadTool:读文件内容FileEditTool:按 patch 方式改文件FileWriteTool:直接写整个文件GlobTool:按文件名、路径模式找文件GrepTool:按关键词搜代码内容
这一组工具负责最基本的两件事:读和写。读项目文件,写项目文件。
第二类,环境工具。
代表就是 BashTool。
这个工具不是拿来替代所有工具的, 而是负责那些必须进真实开发环境才能做的事,比如:
-
跑测试
-
跑构建
-
看 git 状态
-
启动服务
-
执行脚本
-
WebSearchTool:直接联网搜索信息 -
WebFetchTool:获取具体网页内容
这一组工具,是在帮 Claude Code 连接外部环境,获取更多信息。
第三类,会话工具。
这类工具不一定直接改代码,但它们决定整个任务怎么推进。
比如:
AskUserQuestionTool:拿不准的时候停下来问你EnterPlanModeTool:先进入规划模式,不急着动手ExitPlanModeTool:把计划提交出来,准备进入执行TodoWriteTool:把待办拆出来,方便跟踪进度
这一组工具让 Claude Code 不只是“埋头写代码”, 而是更像一个会汇报、会规划、会确认的工程搭档。
第四类,协作和扩展工具。
这是 Claude Code 比较像 Agent 平台的地方。
比如:
AgentTool:把一个子任务分给新的 Agent 去做TaskCreateTool、TaskUpdateTool这些:管理任务状态ListMcpResourcesTool、ReadMcpResourceTool:读取 MCP 服务暴露出来的资源SkillTool:调用预定义技能
这一组工具说明,Claude Code 不是只会单线程地干一件事, 它已经在往“调度、分工、协作”的方向走了。
我们把这些工具放在一起看,就会发现 Claude Code 的工作方式其实很像一个小团队:
- 先搜索
- 再读取
- 再修改
- 改完去验证
- 拿不准就问你
- 复杂任务就拆出去
Claude Code 之所以强大,离不开它背后这一整套分工明确的工具箱。
第四块:上下文管理
接下来我们来看看非常核心的上下文管理。
随着对话越来越长,上下文窗口迟早会被撑满,这是所有长会话 Agent 都必须解决的问题。
Claude Code 的解法藏在 services/compact/ 这个目录里。
先说压缩的触发时机:
// services/compact/autoCompact.ts 第 30、33 行
const MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000
export function getEffectiveContextWindowSize(model: string): number {
const reservedTokensForSummary = Math.min(
getMaxOutputTokensForModel(model),
MAX_OUTPUT_TOKENS_FOR_SUMMARY, // 最多预留 2 万 token 给摘要
)
// 有效窗口 = 模型总窗口 - 预留摘要空间
return contextWindow - reservedTokensForSummary
}
Claude Code并不是等上下文真的满了才开始处理,而是提前算好:现在的上下文量,如果触发压缩,还有没有足够的空间让模型输出摘要?
没有的话,提前触发压缩,保证摘要阶段模型有足够的 token 可以用。
这一点很好理解,因为压缩本身也是要让AI工作并占用上下文的,如果等满了再压缩就来不及了。
注意看代码这里,预留 20000 个 token给执行压缩使用,这个数字不是拍脑袋定的——注释里写了,这是根据历史数据,压缩摘要输出在 99.99% 情况下不会超过 17387 tokens,因此再加一点余量,把上限设为 20000。
压缩具体怎么做的,来看这个流程图:
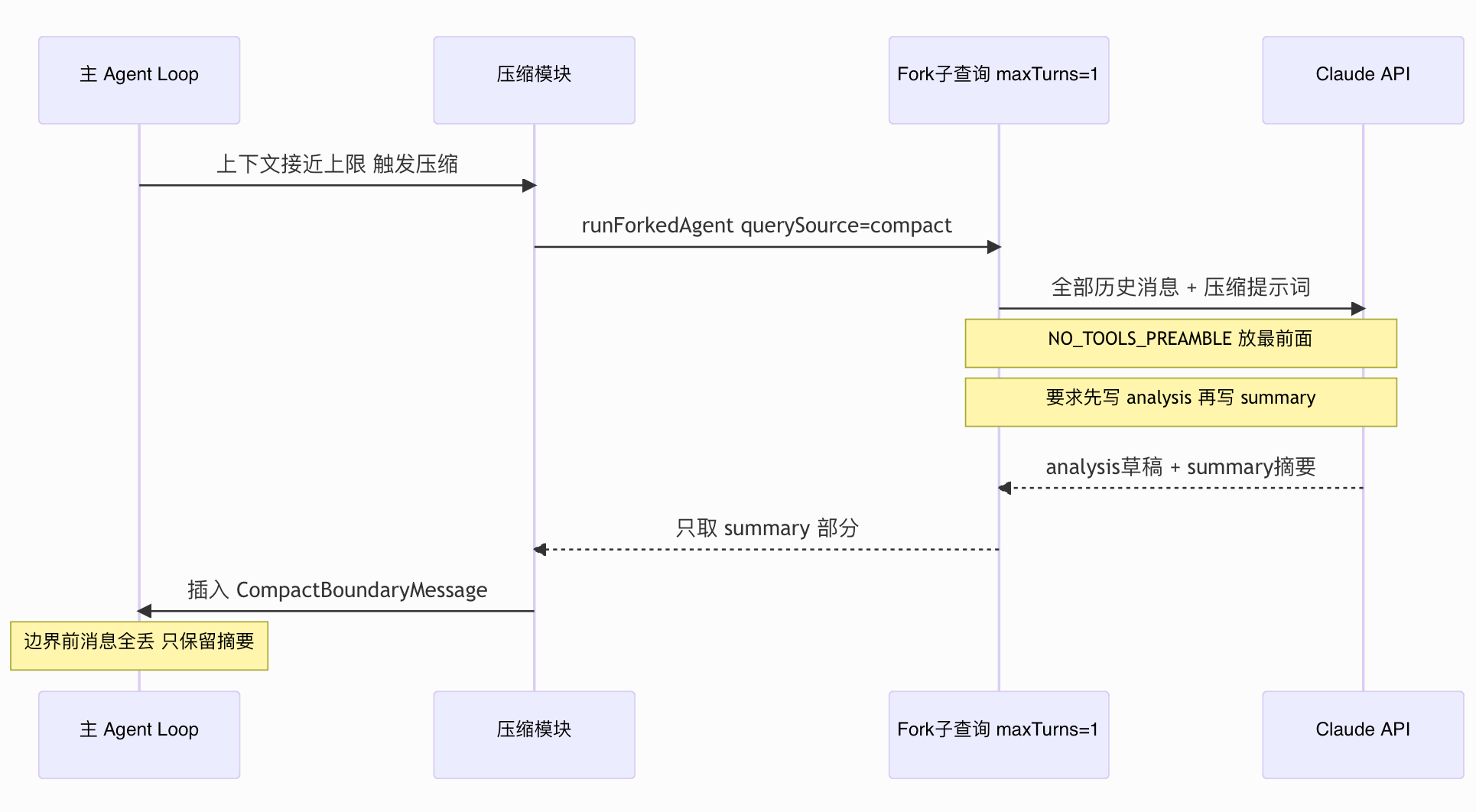
它单独开了一个新的对话,最多只允许一轮,没有任何工具权限,只有一个任务:写摘要。
来看实际代码:
// services/compact/compact.ts 第 1188 行
const result = await runForkedAgent({
promptMessages: [summaryRequest],
cacheSafeParams,
canUseTool: createCompactCanUseTool(), // 工具全部拒绝
querySource: 'compact',
forkLabel: 'compact',
maxTurns: 1, // 只有一次机会
skipCacheWrite: true,
overrides: { abortController: context.abortController },
})
为什么要单独开个新对话,而不是直接在当前对话里做?
如果在主对话里压缩,压缩过程本身也在消耗 token、产生新消息,浪费上下文。
开个独立对话去做,主流程完全不知道压缩发生了,也不会被它干扰,让上下文保持干净。
摘要提示词要求模型先写 <analysis> 打草稿,再写 <summary> 作为最终保留内容。<analysis> 块的作用是强制模型做结构化思考,不让它跳过中间步骤直接输出摘要,实践下来摘要质量会高很多。
最后还有一个电路熔断:
// services/compact/autoCompact.ts 第 261、341 行
// 连续失败达到阈值,停止重试
if (tracking.consecutiveFailures >= MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES) {
return { wasCompacted: false } // 熔断,直接跳过
}
// 成功时重置计数
return { wasCompacted: true, consecutiveFailures: 0 }
// 失败时递增
const nextFailures = prevFailures + 1
if (nextFailures >= MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES) {
logForDebugging('circuit breaker tripped — skipping future attempts')
}
return { wasCompacted: false, consecutiveFailures: nextFailures }
这叫"熔断"——连续失败超过阈值,直接放弃重试,不再白白消耗资源。
这个阈值 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3 是怎么定出来的?
源码注释里有原始数据:历史上有 1,279 个会话在单次会话里连续失败超过 50 次,最极端的一个连续失败了 3,272 次,换算下来全球每天白白浪费约 25 万次 API 调用。
加了这三行代码之后,这 25 万次全省掉了。
Claude Code之所以更好用,细节就藏在这些基于大数据统计做的设计上了。
第五块:MCP
Claude Code 本身已经有很多内置工具了,比如读文件、改文件、跑命令。
但真实开发里,总会遇到它原生不会的东西:
- 公司内部系统
- 团队自己的数据源
- 外部服务
- 远程资源
这时候怎么办?
答案就是 MCP。
它的作用就是:把外部能力,接进 Claude Code 里面来。
MCP 是 Model Context Protocol,模型上下文协议,一套规定外部工具如何接入Agent中的协议。我之前有做过一期视频,通过动画形式快速了解MCP,感兴趣的同学可以进主页观看。
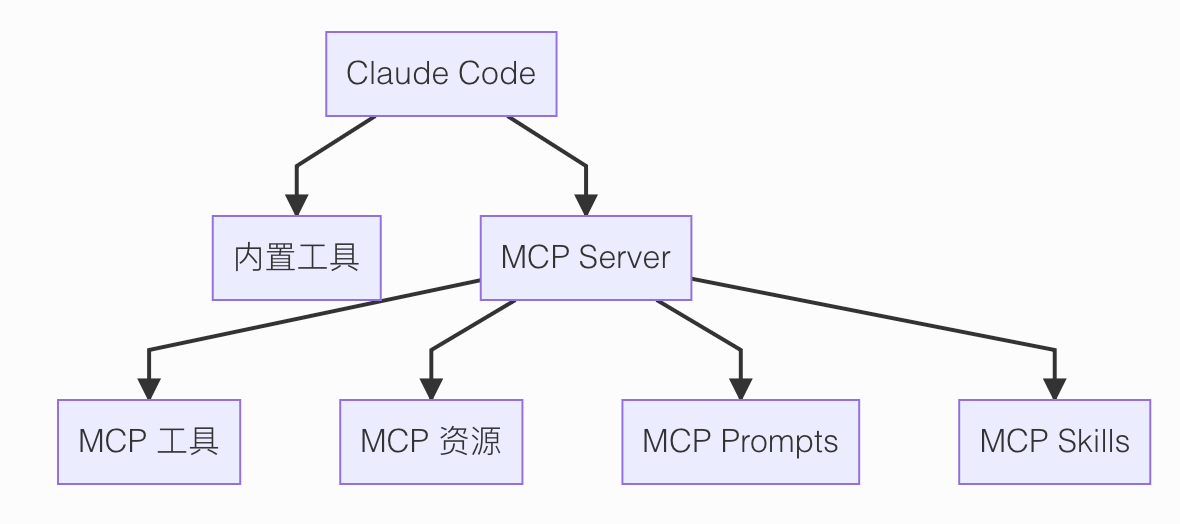
源码里 services/mcp/client.ts 很关键。
这个文件本质上就是 Claude Code 的 MCP 客户端。
它支持多种连接方式:
stdio,连本地子进程http和sse,连远程 MCP 服务ws,走 WebSocket
MCP 接进来之后,Claude Code 不会把 MCP server 原始返回的数据直接扔给模型。
它会先去拉:
tools/listresources/listprompts/list
然后把这些能力翻译成 Claude Code 自己运行时认识的对象。
比如 tools/list 拉回来的每个 MCP 工具,都会被包装成统一的 Tool 对象。
包装完以后,对模型来说,它和 BashTool、FileReadTool 这种内置工具就站到同一个层面了。

第六块:Skills
最后一块说一下 Skills。
关于Skill技术,我之前也有出过一期视频,通过一个动画帮你了解,感兴趣的同学可以进主页观看。
你可以把 Skill 理解成一张“任务说明书”。
这张说明书通常写在 SKILL.md 里,里面会告诉 Claude:
- 这个技能适合什么场景
- 应该怎么做
- 允许用哪些工具
所以 Skill 不是单纯多了一段提示词, 而是把一套经验、一套流程,正式做成了系统能力。
现在很多公司员工离职交接都不是像以前写文档了, 而是写Skill,把你日常的工作写成Skill,人离职了,Skill留下了。
Skill的第一步,是加载。
Claude Code 启动时,会去几个固定位置扫描 Skills,
把这些 SKILL.md 文件全部读出来,解析之后,再统一变成内部的 command 对象。
简单理解就是:

也就是说,Skill 在系统眼里不是一篇普通 Markdown 文档, 而是一个可以被调度、可以被执行的正式命令。
第二步,是发现。
这一步很关键。
Claude Code 并不是把所有 Skill 内容一股脑塞进上下文, 而是先把 Skill 的名字和简介放进可用列表里。
模型先知道:
- 现在有哪些 Skill 能用
- 它们大概是干什么的
等它判断当前任务确实需要某个 Skill,
才会真正调用 SkillTool 去展开这个 Skill 的完整内容。
这就是它很聪明的一点:
这样既省上下文,也更灵活。
第三步,才是执行。
Skill 真正执行的时候,核心入口就是 SkillTool。
它干的事情大概是这几步:
- 先根据名字找到对应的 Skill
- 检查这个 Skill 能不能执行
- 把 Skill 里的完整说明展开出来
- 决定是在当前上下文里直接执行,还是开一个子 Agent 去执行
- 最后把结果回给主流程
可以看这张图:
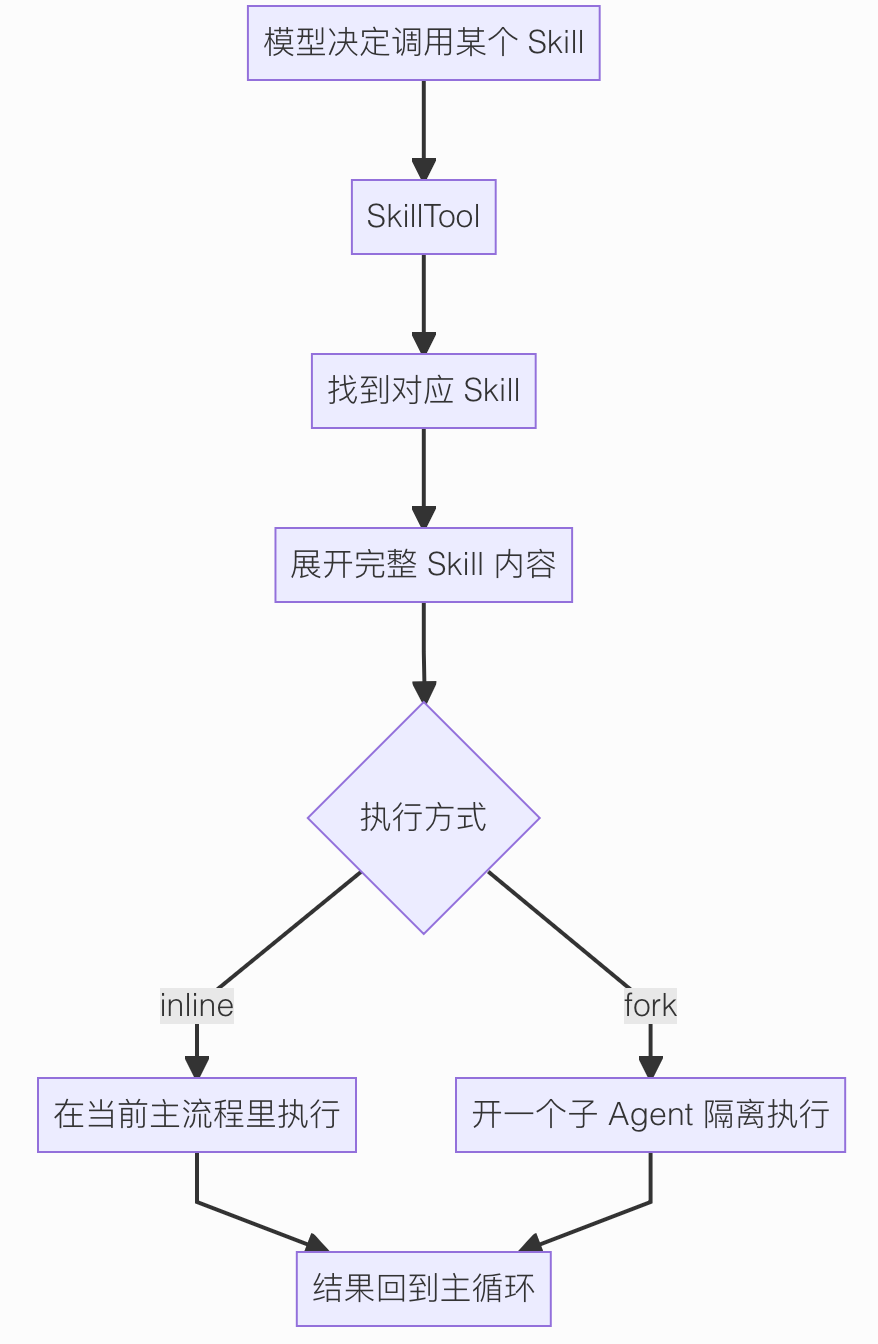
这里最值得记的就是 inline 和 fork 两种模式。
inline 很好理解,
就是把 Skill 直接展开到当前对话里,主 Agent 接着往下做。
fork 就更有意思了。
如果一个 Skill 比较复杂,Claude Code 可以专门开一个子 Agent, 让它在独立上下文里把这件事做完,再把结果回传回来。
这么看起来的话,Skill 不只是“多了一段提示词”, 它甚至已经带了一点轻量多 Agent 的味道。
主线程继续当总控, 复杂 Skill 丢给子线程处理, 处理完再汇总回来。
最后有一个彩蛋
骂 Claude Code 会被偷偷记录。
在utils目录下的userPromptKeywords.ts文件,这里会检测你输入的消息里有没有"wtf"、"fuck you"、"this sucks"这类词。
检测到之后,Claude Code 的行为不会有任何变化——它还是正常帮你干活——但会静默记录一个 is_negative: true 的标记,打包发给后台分析系统。
哎别着急,这可不是要给你记小本本将来封你号。
Claude Code 的作者在源码泄露后接受采访时亲口说了:"这是我们判断用户体验是否良好的信号之一,我们管它叫 fucks 图。"
Anthropic这收集数据做分析的能力,不得不服,一般人哪能想到这个。
最后说几句
OK,六大模块终于说晚了。这次连夜扒代码给我最大的感受是:
Claude Code 不是一个"套 API 套出来"的工具,而是一个工程化程度相当高的 AI 操作系统,每一个设计决策背后都有明确的理由。
工具默认"不安全",安全要显式声明,别默认信任。
循环要设双重熔断,轮次和预算一起卡,少一个都容易翻车。
上下文压缩单独开新对话做摘要,别在主流程里搞,否则越压越大。
权限决策链分层,Hook 拦一层、分类器判一层、用户确认兜底,每层各司其职。
因为时间仓促,分析的深度还不够,更详细的分析欢迎大家去看这份完整的教程,地址已经放到视频下方了,感兴趣的朋友可以去翻翻看。
学习地址:
https://www.xuanyuancode.com/learn-claude-code
好了,今天就分享到这里。
如果觉得还不错的话,别忘了点赞投币支持一下。
路过的朋友欢迎点个关注,我是轩辕,我们下期再见~