Transformer 架构
把注意力、FFN、残差拼在一起——2017 年那篇论文到底做了什么?
注意力已经很强了,为什么还不够?
前两课我们已经造出了一个很厉害的部件:注意力。它让句子里的每个词都能回头看别的词, 于是「它」终于知道自己指的是谁;再加上多头,模型还能同时盯住指代、语法、情绪这些不同关系。
到这里,一个很自然的问题就来了:既然注意力已经能让词彼此看见,为什么 Transformer 还要加别的零件?为什么不是“几层注意力一叠”,事情就结束了?
这一课我们不背整张结构图,也不一上来扔一堆术语。只做一件事:围着一句最简单的话,亲手把一台最简 Transformer 搭出来,并且看清它身上每个零件到底是被什么问题逼出来的。
输入:「我 是 一只 小 ___」
目标:预测下一个词
先搭最朴素的一版:只有注意力
先别急着加零件。我们先来搭一个最朴素的版本试试看:把「我 / 是 / 一只 / 小」这几个词变成向量, 丢进一层注意力,让每个词去看别的词、把相关信息混进自己;再叠几层,最后拿最末尾那个位置的向量去预测下一个词。
这个想法很顺。因为预测「小 ___」后面该接什么,确实需要前文信息: 「我 是 一只 小」看完整体之后,模型大概率会觉得「猫」「狗」「鸟」之类的词比较像答案。
但问题也正卡在这里:注意力能把信息汇总过来,却不等于它已经会“加工”这些信息。先把这一点盯牢。
注意力算到最后,每个词拿到的新向量,本质上是别的词的 按权重做的一次加权平均。 也就是说,它更像是在已有信息之间重新分配比重,而不是凭空造出一个全新的判断。
用回我们的例子:注意力当然能让最后那个位置看到「我」「是」「一只」「小」这些上下文, 但它看到之后,还需要一个部件来把这些线索整理成更明确的特征,比如“这大概率在说某种小动物”。
这一步的思路,其实和第 16 课一模一样。那一课我们发现:N-gram 只会查表,查到之后不会推断, 所以才把卷二早就学过的全连接网络接上去,让它把“查来的数字”再加工一遍。这里也一样:注意力只负责把相关词找来、混到一起;可“找来之后怎么办”,它自己不负责。
一旦把缺口说清楚,补件其实几乎是顺手拈来的:我们卷二已经有现成的“加工器”了。 它会做三件注意力自己不擅长的事:加权、过非线性、把结果压成新的表示。 换句话说,注意力负责收集材料,那下一个自然该接上的,就该是一个负责处理材料的网络。
补上第一块零件:FFN
这时候就轮到第二个部件出场了:FFN(前馈网络)。它不是拿来让词和词通信的, 而是让每个词各自在拿到上下文之后,再做一轮自己的内部加工。
所以这里不是“凭空又塞了一个模块”,而是顺着缺口往下补:谁负责收集上下文?注意力。谁负责把收集来的东西再算一遍?FFN。这和第 16 课“查向量之后,为什么自然要接一个神经网络”是同一种写法。
你可以把一层 block 想成两步,分工非常清楚:
- 注意力:横向,负责“去看别人”。
- FFN:纵向,负责“拿到信息后自己再想一遍”。
所以 FFN 不是配角,而是必需品。没有它,你只有“把相关信息拉过来”这一步;有了它,模型才多了“把拉来的信息重新整理成更好表示”这一步。
论文里 FFN 常写成 512 → 2048 → 512:先把维度撑大到 4 倍,过一道 ReLU,再压回原样。为什么要这么折腾?看个具体例子就懂了。
先看清楚 FFN 拿到的「小」是什么。它不是词表里那个孤零零的「小」,而是刚过完注意力、已经把前文「我 是 一只」的信息揉进来的一个 512 维向量——里面其实暗藏着好几条线索: 前面出现过「一只」、出现过「小」、整句在讲「我」……只是这些线索挤成一团、藏在那 512 个数字里,还没被读出来。
FFN 要做的,就是把这些暗藏的线索一条条识别出来,合起来判断「下一个词会不会是某种小动物」: 有没有「一只」(在点数一个个体)?有没有「小」(体型偏小)?像不像在讲宠物?撑到 2048 维,就是一次摆开两千多个这样的「小检测器」,每个查一条线索;ReLU 把查到的留下、没查到的清零; 最后第二个矩阵把亮着的线索汇总成一句结论「大概率接小动物」,再压回 512 维交出去。
所以两次变维,各有各的用处:撑大,是因为 512 维塞不下这么多检测器、线索一多就照顾不过来;压回,是因为下一个 block 接的就是 512 维,不收拢回去就接不上。(至于偏偏是 4 倍,是试出来的经验值,记住套路就行。)
这一步还有个重要副作用:FFN 里塞满了参数,因此模型很多“内部知识”也会沉在这里。但对这一课来说,你先记住更关键的分工就够了:attention 管通信,FFN 管加工。
把它们拼起来:最简 Transformer 主干
到这里,block 的主干已经出来了:一个词进来,先和别的词交换信息,再自己做一轮加工。把这两个步骤首尾接起来,就是一个 Transformer block。
而且这个 block 有个非常妙的性质:输入和输出维度一样。这里说的“输入”,不是一句话的汉字本身, 而是这一整排词向量;“输出”则是这排词向量各自经过 attention 和 FFN 之后的新版本。 比如这句「我 / 是 / 一只 / 小」,现在正好有 4 个 token;如果每个词向量是 512 维,那么这一轮一个 block 吃进去的是4 × 512,吐出来的仍然是4 × 512: 还是 4 个位置、每个位置还是 512 个数,只不过每个位置里的内容都被更新过了。
但要注意,4 只是这句例子的长度,不是 Transformer 固定只吃 4 个词。更一般地,一个 block 处理的是n × 512 这样一整张表:n 是这次实际喂进去的 token 数,512 是每个 token 向量的维度。 句子短,n 就小;句子长,n 就大。唯一的限制是 n 不能超过模型允许的最大上下文长度,不可能无限长。
正因为形状没变,一个 block 的输出才能原封不动地送进下一个 block。于是它天然就适合一层一层往上叠。
现在把整个流程接完整:
- 先把「我 / 是 / 一只 / 小」查词表,变成一排向量。
- 过几层 block,让这些向量反复交换信息、反复加工。
- 取最后一个位置的输出向量,去预测“下一个词是谁”。
这就是 GPT 式生成的核心:先算出「猫 31%、狗 22%、鸟 12%……」,挑一个结果接到句尾, 再把整句重新送进去,继续预测下一个词。于是文本就是这样一个词一个词往外长出来的。
到这里你应该已经抓住主干了:Transformer block = attention + FFN,并且可以堆叠。但这台机器还埋着一个马上会翻车的坑。
它马上翻车了:模型不知道谁在前谁在后
问题恰好出在我们刚刚夸过的优点上:并行。Transformer 能把一整排词同时送进去算, 不像 RNN 那样一个个排队,这让它特别适合 GPU,也特别适合做大。
但“同时处理”也带来副作用:如果你只给词向量,不额外告诉它位置,注意力本身并不知道顺序。
这两句用的是同一批词,意思却完全反过来。可如果模型只看到一袋词和它们的向量, 那它根本不知道“猫”是在前面还是在后面,“狗”是在宾语位置还是主语位置。
这就逼出了第三块零件:位置编码。方法很直接:在送进第一层注意力之前, 先给每个词向量加上一份“我是第几个”的信息。
这样一来,“猫@位置0”和“猫@位置2”就不再是同一个向量,“猫追狗”和“狗追猫”也终于会被模型区分开。
原始论文用的是正弦/余弦位置编码;后来的模型还会用可学习位置向量、RoPE 等做法。实现细节可以变化, 但目的始终没变:告诉模型“这些词不只是同时出现,它们还有先后次序”。
到这里,一台最简 Transformer 就拼出来了
现在回头看,整个结构已经很清楚了:
- 词向量负责告诉模型“这是什么词”。
- 位置编码负责告诉模型“它排第几个”。
- 注意力负责让词与词交换信息。
- FFN负责让每个词在拿到信息后自己再加工一遍。
- 多层堆叠负责把这件事反复做深。
- 末尾线性层 + softmax负责把最后一个位置变成“下一个词的概率表”。
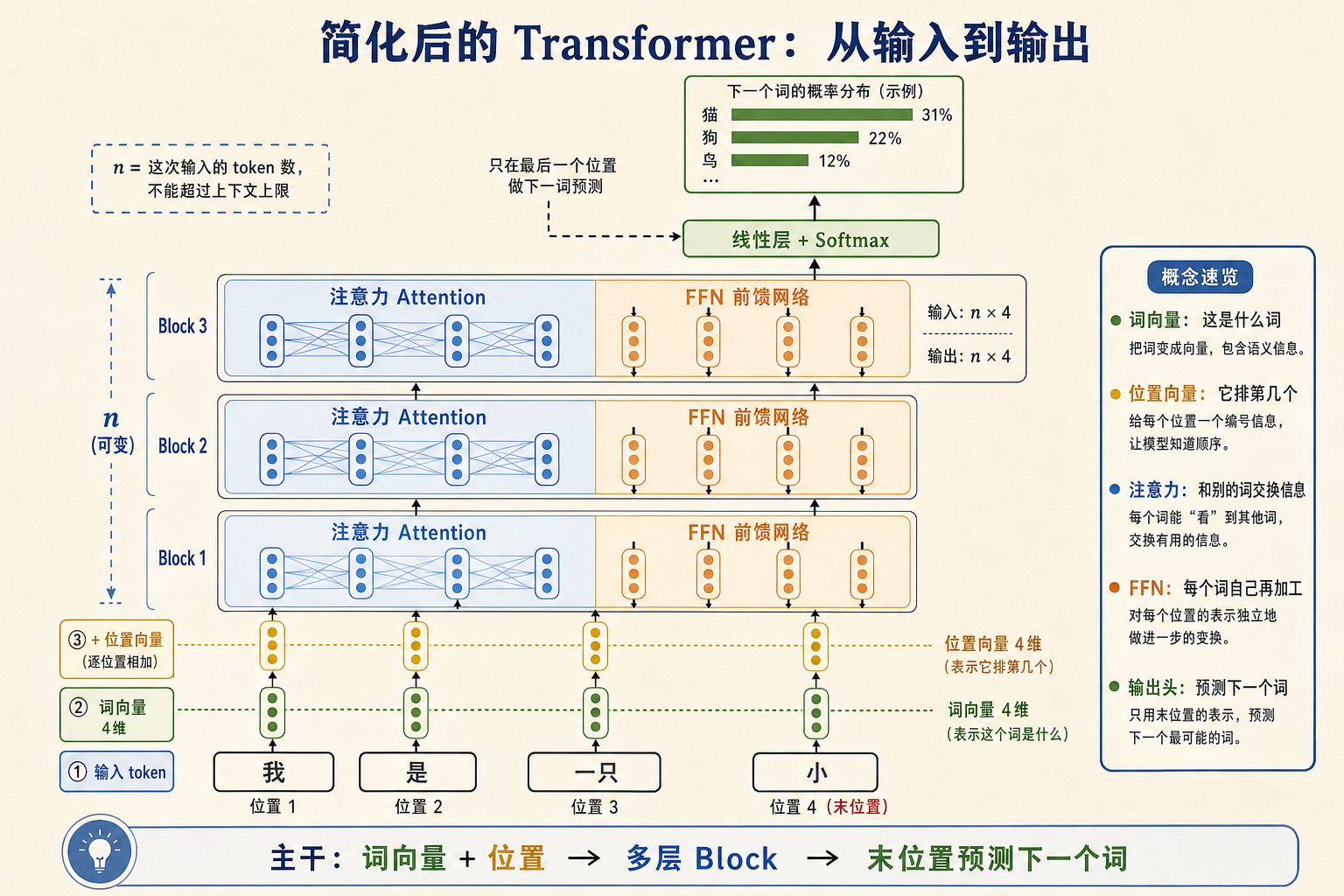
这已经是一台能跑的 Transformer 主干了。它能并行、能堆深、能做“预测下一个词”这种任务, 这正是后来 GPT 一路做大的出发点。
当然,真实模型还没讲完。为了突出主线,我们这节课有意省掉了两个重要细节:比如 block 里真正的Add & Norm 稳定器,以及生成时的掩码等机制。这些不是不重要,而是值得拆到后面单独讲。
所以这节课的任务不是“把全部细节一次吞下”,而是先把主骨架梳理出来,有一个大体的印象。
总结
Transformer 不是“只有注意力”。一台最简 Transformer 至少包含三样东西:注意力负责让词与词通信,FFN负责让每个词在拿到上下文后继续加工,位置编码负责把顺序信息塞回输入。 把这样的 block 一层层叠起来,再接上线性层和 softmax,就能像 GPT 那样一步步预测下一个词。
这一课你真正应该带走的是
- 只靠注意力还不够:它能汇总上下文,但还缺少“汇总后的逐词加工”。
- FFN 的职责:每个词各自做一轮非线性加工,所以 block 不是 attention-only。
- 一个 block 的骨架:attention(横向通信)+ FFN(纵向加工)。
- 顺序必须额外补回:没有位置编码,模型分不清“猫追狗”和“狗追猫”。
- 最简 Transformer 主干:词向量 + 位置信息 → 多层 block → 末尾预测下一个词。
学习小测验
做完这一课,来检测一下核心知识点。选出你的答案后点击「提交」,即可看到正确选项与讲解。
Tokenizer 分词器
这一课我们一直假设“词可以直接变成向量”。可模型真正看到的单位到底是什么?下一课把这个入口补上。